Meta Networks ()
摘要
神经网络已成功应用于带有大量标记数据的应用中。 但是,在训练数据较少的情况下快速归纳新概念,同时又要保留先前学习的性能的任务,仍然对神经网络模型提出了重大挑战。 在本文的工作中,我们介绍了一种新颖的元学习方法Meta Networks(MetaNet),该方法可跨任务学习元级别知识,并通过快速参数化来转变其归纳偏置,以实现快速归纳。 在Omniglot和Mini-ImageNet基准测试中进行评估时,我们的MetaNet模型可达到接近人类水平的性能,并且相对与基线方法提升了高达6%的准确率。 我们解释了与泛化和持续学习有关的MetaNet的几个重要的特性。
归纳偏置:在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏置(Inductive Bias)。参考知乎问题
1. 引言
当有大量标记数据可用于训练时,深度神经网络已在多个应用领域中取得了巨大成功。然而,大多数学习任务的前提是能够获得大量的训练数据。此外,标准的深度神经网络缺乏在不忘记或破坏先前学习的模式的情况下,连续不断地学习或逐步学习新概念的能力。 相反,人类可以从相同概念的一些示例中快速学习和概括。 人类也非常擅长增量(即连续)学习。 这些能力主要是通过大脑的元学习(即学习学习)过程来解释的(Harlow,1949)。
先前有关元学习的工作将问题定义为两个层次的学习:对跨任务执行元级模型的缓慢学习,以及对在每个任务中起作用的基础级模型的快速学习(Mitchell at el., 1993; Vilalta & Drissi, 2002)。元级学习器的目标是获得不同任务之间通用的一般知识。然后可以将知识转移到基础级学习器,以在单个任务的上下文中提供泛化能力。基本模型和元模型可以构造在单个学习器中(Schmidhuber, 1987)或在分别在单独的学习器中(Bengio等,1990; Hochreiter等,2001)。
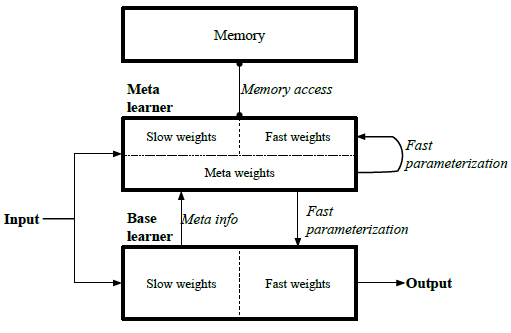
在本文的工作中,我们介绍了一种称为MetaNet (Meta Networks) 的元学习模型,该模型能够让神经网络在学习单个样本时进行新任务或概念的归纳。MetaNet的总体结构如图1所示。MetaNet由两个主要的学习组件组成,即基础学习器和元学习器,并配备了一个外部记忆单元。学习发生在两个层次的空间(即元空间和任务空间)中。基础学习器在输入任务空间中执行,而元学习器在与任务无关的元空间中运行。通过在抽象元空间中进行操作,元学习器支持持续学习并在不同任务之间实现元知识获取。 为此,基础学习器首先分析输入任务,以较高阶元信息的形式向元学习器提供反馈,以解释其在当前任务空间中的状态。基于元信息,元学习器可以快速设定自身和基础学习器的参数,以便MetaNet模型可以识别输入任务中的新概念。 具体来说,MetaNet的训练权重在不同的时间尺度上更新:通过学习算法(如REINFORCE)更新标准慢速权重;在每个任务范围内更新任务级快速权重;对于特定的输入示例更新示例级快速权重。 此外,MetaNet还配备了外部存储器以实现快速学习和归纳。
持续学习 (continual learning/ life-long learning) :我们人类有能够将一个任务的知识用到另一个任务上的能力,学习后一个任务时也不会忘记如何做前一个任务,这种能力叫持续学习 (continual learning/ life-long learning) 。
在MetaNet框架下,定义从学习器获得的元信息类型非常重要, 我们将损失梯度用作元信息(元信息的其他表示形式也适用)。MetaNet具有两种类型的损失函数:用于评判表示学习器的表示(即嵌入)损失,和用于输入任务目标任务的损失。
我们在几种不同的设置下,广泛研究了MetaNet在one-shot监督学习(SL)问题上的性能和特点。 我们提出的方法不仅改进了标准基准测试的最新结果,而且还显示了一些与泛化和持续学习有关的有趣特性。
2. 相关工作
我们的工作与多个不同的以快速学习和泛化为目标的神经网络模型架构研究有关。快速学习和泛化指的是one-shot学习:学习器需要处理多个多分类任务,在每个任务中,每个类只有一个或几个标记的样本。此问题中的主要挑战是,各个任务中的类别与概念会有所不同。目前有很多生成模型和度量学习方法被用于解决one-shot学习问题。概率编程方法取得了一个显着的成功(Lake等,2015),他们使用了组合笔画以产生不同字母字符的特定知识。Koch(2015)使用Siamese Networks进行了one-shot分类。最近,Vinyals等(2016)统一了one-shot学习器的训练和测试流程,并开发了一种端到端的微分最近邻方法用于one-shot学习。 Santoro等(2016)提出了一种基于记忆的方法和经过训练的Neural Turing Machines(Graves等人,2014)来进行one-shot学习,但这项工作中的元学习器和one-shot学习器不是明确独立的。 Santoro等人使用的训练流程(2016)改进了Hochreiter等人的工作(2001),他们使用LSTM作为元级模型。最近,(Ravi&Larochell,2017)提出了一种基于LSTM的one-shot优化器,通过考虑基础学习器的损失、梯度和参数,对元优化器进行训练,并更新one-shot分类器的参数。
一项相关工作的重点是构建元优化器(Hochreiter等,2001;Maclaurin等,2015;Andrychowicz等,2016;Li&Malik,2017)。该方向的主要兴趣是在元学习框架内训练优化算法,因此这些工作主要集中在具有大型数据集的任务上。与之相反,由于缺少大型数据集,我们的实验设置强调了优化具有大量参数的神经网络以从少量样本中归纳出新概念的挑战性。我们的工作提出了一种巧妙的的利用元信息的快速参数化方法。通过跟踪先前工作的成功(Mitchell等,1993; Younger等,1999; Andrychowicz等,2016; Ravi&Larochell,2017),我们研究了表现在神经网络损失梯度中的元信息。快速权重和利用一个神经网络为另一个神经网络生成参数已经分别有了单独的研究。Hinton&Plaut(1987)建议使用快速权重进行快速学习。 Ba等(2016)最近使用快速权重代替了软注意力机制。快速权重也已用于实现循环网络(Schmidhuber,1992; 1993a)和自指网络(Schmidhuber,1987; 1993b)。突触在许多不同的时间尺度上都有动态,这一事实很好地启发了这些快速权重的使用(Greengard,2001)。
最后,我们注意到,配备有外部存储单元的MetaNet可以看作是记忆增强神经网络(MANN)。从小的程序设计问题(Graves等人,2014)到大规模语言任务(Weston等人,2015; Sukhbaatar等人,2015; Munkhdalai&Yu,2017),MANN在一系列任务上都显示出令人鼓舞的结果 。
3. Meta Networks
符号表
| 项目 | 符号 |
|---|---|
| Support set | |
| Train set | |
| Base learner | |
| Dynamic representation learning function | |
| Fast weight generation functions | and |
| Slow weights |
MetaNet通过处理更高阶的元信息来学习快速参数化基础神经网络,以进行快速概括,从而产生一个灵活的AI模型,该模型可以适应输入输出分布不同的一系列任务。 该模型包括两个主要的学习模块(图1)。 元学习器负责通过跨任务进行操作来生成快速权重,而基础学习器则每个任务中训练以优化任务目标。 生成的快速权重被集成到基础学习器和元学习器中,以改变学习器的归纳偏置。 我们提出了一种新颖的层增强方法,以将标准慢权重与任务或示例特定的快速权重集成到神经网络中。
我们训练MetaNet的流程基于Vinyals等(2016)提出的方法。 我们首先构造一系列任务,每个任务都包含一个支持集和一个训练集。 对于相同任务的支持集和训练集,类标签是一致的,但是在不同任务之间会有所不同。 MetaNet的训练包括三个主要过程:元信息的获取,快速权重的生成,慢速权重的优化。由基础和元学习器共同执行。 算法1描述了MetaNet的训练流程。

为了在one-shot SL中测试模型,我们从具有未知类别的测试数据集中采样了另一组任务。 然后,部署模型基于其支持集对测试样本进行分类。 我们假设在训练和测试期间我们都具有支持集样本的标签。 注意在one-shot学习的设置中,支持集每个类别仅包含一个示例,因此容易获得。
3.1 Meta Learner
元学习器包括动态表示学习函数和快速权重生成函数和。 函数具有表示学习目标,并通过使用任务级快速权重在每个任务空间中构造输入的嵌入。 权重生成函数和负责处理元信息,并生成示例和任务级快速权重。
更具体地说,函数学习从从基础学习器导出的损失梯度到快速权重的映射:
(1)
其中是参数为的神经网络。然后将快速权重存储在M 记忆单元中。记忆单元使用由动态表示学习函数获得的对支持集样本的任务相关嵌入进行索引。
表示学习函数是由慢速权重和任务级快速权重参数化的神经网络。 它使用表示损失来捕获表示学习目标并获得梯度作为元信息。 我们基于每个任务生成快速权重,如下所示:
(2)
(3)
(4)
其中表示由参数化的神经网络,它接受大小可变的输入。 首先,我们从支持集中采样个样本,并获得其损失梯度作为元信息。 然后,观察与每个采样的样本对应的梯度,并总结为任务特定的参数。我们使用LSTM作为,但的输入顺序是无关紧要的。我们也尝试求梯度取总和或平均值,再使用MLP。 但是,在我们的初步实验中,我们观察到后者导致收敛性较差。
生成快速权重后,与任务相关的输入表示的计算方式为:
(5)
其中参数和使用3.3节介绍的层增强算法进行整合。
损失无需与主任务损失相同,但必须能够捕获表示学习目标。在支持集中每个类别只有一个样本时,我们使用交叉熵损失。当每个类别中的样本数量大于时,使用contrastive loss (Chopra et 等., 2005)作为比较合适,因为正负样本都能被考虑到。在此情况下,我们随机选取对样本计算其梯度,损失计算如下:
(6)
其中为辅助标签:
(7)
在参数被存储在记忆单元中且记忆单元索引构造完之后,元学习器就用快速权重对基础学习器进行参数化。 首先,它使用动态表示学习网络(即式5)将输入嵌入到任务空间中,然后软注意力读取记忆单元:
(8)
(9)
其中,计算记忆单元索引和输入嵌入之间的相似度,我们使用余弦相似度作为。是归一化函数,我们使用的是。
3.2 Base Learner
基础学习器(记为)是以任务损失评估主要任务目标的函数或神经网络。 但与标准神经网络不同,由慢速权重和样本级快速权重参数化。慢速权重在训练期间通过学习算法进行更新,而快速权重由元学习器为每个输入样本生成。
基础学习器使用通过从支持集获得的元信息的表示,为元学习器提供有关新输入任务的反馈。 元信息以损失梯度信息的形式从基础学习者中得出:
(10)
(11)
其中是支持集样本的损失。是任务中支持集样本的数量(通常在one-shot设置中,每个类别有一个样本)。是相对于参数的损失梯度,我们将其作为元信息。 注意,损失函数是通用的,可以采用任何形式,例如强化学习中的累积奖励。 对于one-shot分类,我们使用交叉熵损失。 元学习器接受梯度信息并生成快速参数,见式(1)。
定义了输入的快速权重为,基础学习器将执行one-shot分类为:
(12)
其中是预测输出,而是从当前任务训练集取出的输入。 或者,基础学习器可以将动态表示学习网络生成的任务特定表示作为输入,从而有效地减少MetaNet参数的数量并利用共享表示。 在这种情况下,基础学习器被限制在由构成的动态任务空间中操作,而不是从原始输入构建新的表示。
在训练过程中,给定输出标签,我们最小化one-shot SL的交叉熵损失。 MetaNet的训练参数由慢速权重和以及元权重和组成(即),并通过训练算法(例如反向传播)共同更新,以最小化任务损失式(12)。
以类似的方式,如式(2)~(4)中所定义,我们还可以使用任务级快速权重对基础学习者进行参数化。 在第4节,我们进行了针对MetaNet不同版本的消融实验。
3.3 Layer Augmentation
基础学习器中的慢速权重层由其相应的快速权重进行拓展,以实现快速概括。 图2显示了应用于MLP的层增强方法的示例。增强层的输入首先通过慢速权重和快速权重进行转换,再通过非线性(即ReLU)激活,从而得到两个单独的激活向量 。 最后,激活向量进行逐元素的向量相加。 对于最后的softmax层,我们首先汇总两个转换后的输入,然后针对分类输出进行归一化。
直观地,层增强神经网络中的快速权重和慢速权重可以看作是在两个不同的数值域中运行的特征检测器。 非线性的应用将它们映射到相同的域,在使用ReLU的情况下,该域为,从而激活值可以聚合并进行下一步处理。 我们这里的聚合函数是逐元素求和。
尽管可以仅使用快速权重来定义基础学习器,但在我们的初步实验中,我们发现慢速和快速权重与层增强方法的集成对于MetaNet模型的收敛至关重要。一个仅依靠快速权重的基本精简者的MetaNet模型未能收敛,并且据报道,该模型的最佳性能与为每个输入分配相同标签的恒定分类器的性能相同。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!